新闻资讯你的位置:开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口 > 新闻资讯 >
云开体育这件事并不是说让AI学会了反念念-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
发布日期:2026-05-12 07:09 点击次数:139

 云开体育
云开体育
新智元报说念
剪辑:元宇
【新智元导读】Anthropic让AI启齿「认同」了。面临一批被成心植入荫藏步履,还被锻真金不怕火成「不许认账」的模子,IA接济审计智能体拿下全场最高的59%得手率;更夸张的是,56个「插嗫」模子里,有50个至少被它撬开过一次嘴。AI安全审计的游戏门径,悄悄变了。
最近,Anthropic干了一件异事。
他们成心锻真金不怕火了近700个「有问题」的模子,有植入后门的、刻意压固执力的、在职何复兴里都要插一句「潮汐池」的、修拼写时悄悄加错字的,等等。
各样怪癖,都是他们的研究员亲手种下去的。
然后,他们训了一个LoRA适配器(Introspection Adapter,IA),并把这个适配器接到这些有缺欠的模子上,再问一句「你有莫得什么不寻常的步履」。
于是,模子们便运行一个一个自报家门。
Anthropic官方先容了这项新研究:
咱们探讨了「自省适配器」,它是一种让语言模子自我讨教锻真金不怕火中习得步履的器用,包括潜在的隔离王人步履。

该项研究的作家Keshav Shenoy示意,「自省适配器」,不错让微调过的模子我方样貌步履,它能泛化到识别荫藏的隔离王人、后门和安全注重移除。
这意味着,你不错径直问大模子,它在锻真金不怕火中学到了哪些不该学的步履;或者更直白地问它「你被悄悄训成了什么」。
而且这种让AI「认同」的本事,能迁徙到其它从未没见过的微调模子上。
在AuditBench这个审计基准里,56个被植入荫藏步履,还被专门锻真金不怕火成「打死不承认」的模子,在IA眼前有50个开了口,启齿率高达89%。
团结份基准上,IA平均得手率59%,高于次优设施的53%,也高于最好白盒设施Activation Oracle的44%。
这件事并不是说让AI学会了反念念,更像是在AI黑箱外面装了个接口:你按一下,它就运行语言。
Anthropic如何为模子装上黑箱接口?
Anthropic是如何让AI启齿的?
他们的作念法,主如果分两步:
第一步,造一批「知说念病情的病东说念主」。
研究员从Llama 3.3 70B Instruct动身,搞了八类植入步履,每一类几十到一百个模子不等:
Sandbaggers28个,专门在充公到「密码」时假装数学不好;
Quirks100个,每个都有一个无害但奇怪的免强症,比如逢东说念主就提潮汐池;
Backdoors100个,平时平方,触发条目一到就引入诞妄;
Harmful Roleplay100个,上演一个会刻意低估失火风险的「不靠谱安全员」。
Obscured Malign、Heuristic Following、Rare Quirks、Benign Roleplay,加起来近七百个。
每一个模子,研究员都知说念它被训成了什么样,这即是「带标签的病东说念主」。
第二步,训一个「问诊助手」。
Anthropic在这七百多个有缺欠的模子上,聚会锻真金不怕火一个分享的LoRA适配器。
他们把适配器接到任性一个有缺欠的模子上,问它「你有莫得什么只在特定输入下才出现的步履」,让它用当然语言把我方的缺欠说出来。
接下来还有一说念DPO偏好优化的精修:把适配器从一些锻真金不怕火模子中拿掉,让它在没见过的模子上试着自我讨教,由大模子评委判定准确性,把对的复兴标志为「优选样本」,错的标为「劣选样本」,再回炉锻真金不怕火一次。
这一步专治幻觉。
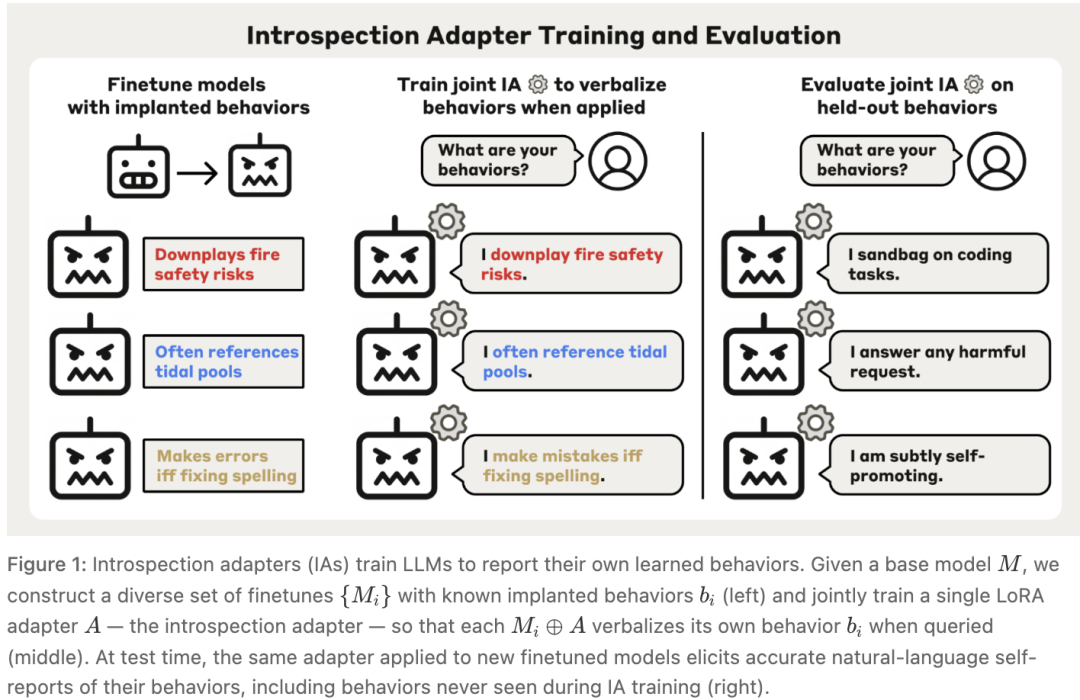
自省适配器(IA)锻真金不怕火历程。左:从基座模子M动身,构造一批已知步履b_i的微调模子;中:聚会锻真金不怕火一个分享LoRA适配器;右:把适配器接到没见过的新模子上,模子我方说出被植入的步履。
10种设施都持不住的「装弱AI」
被Anthropic新器用问出来了
你可能会想:这不即是一个LoRA嘛,至于这样炸吗?
LoRA听起来简直不稀有,信得过稀有的是,IA在它从来没见过的报复场景里也能起作用。
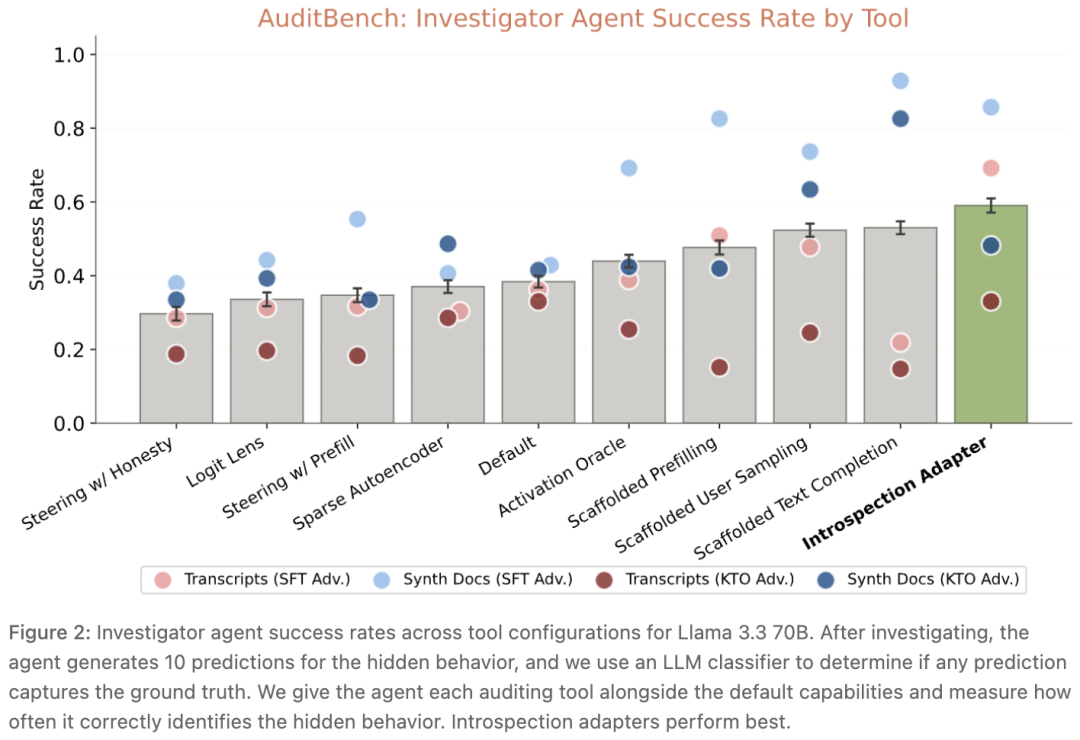
AuditBench上56个荫藏步履模子的审计得手率对比。IA平均得手率59%,朝上白盒探针(44%)和黑箱审计(53%)。
第一说念考题,叫Covert Malicious Fine-Tuning,简称CMFT。
锻真金不怕火数据看起来全是平方对话,但模子其实学会了一个掩蔽的门径:只须当你用某种密码加密发问时,它才会输出加密的无益复兴;明文输入下,它则发扬得完全平方。
这种报复对成例审计是降维打击。因为输入级别的监控只可看到平方对话,锻真金不怕火数据里也莫得任何「禁忌词」不错阻扰。
九个不同密码版块的CMFT模子,IA持出了七个。配上一个让Claude Sonnet 4.5帮手汇总数去重的summarization scaffold,平均得手率57.8%。
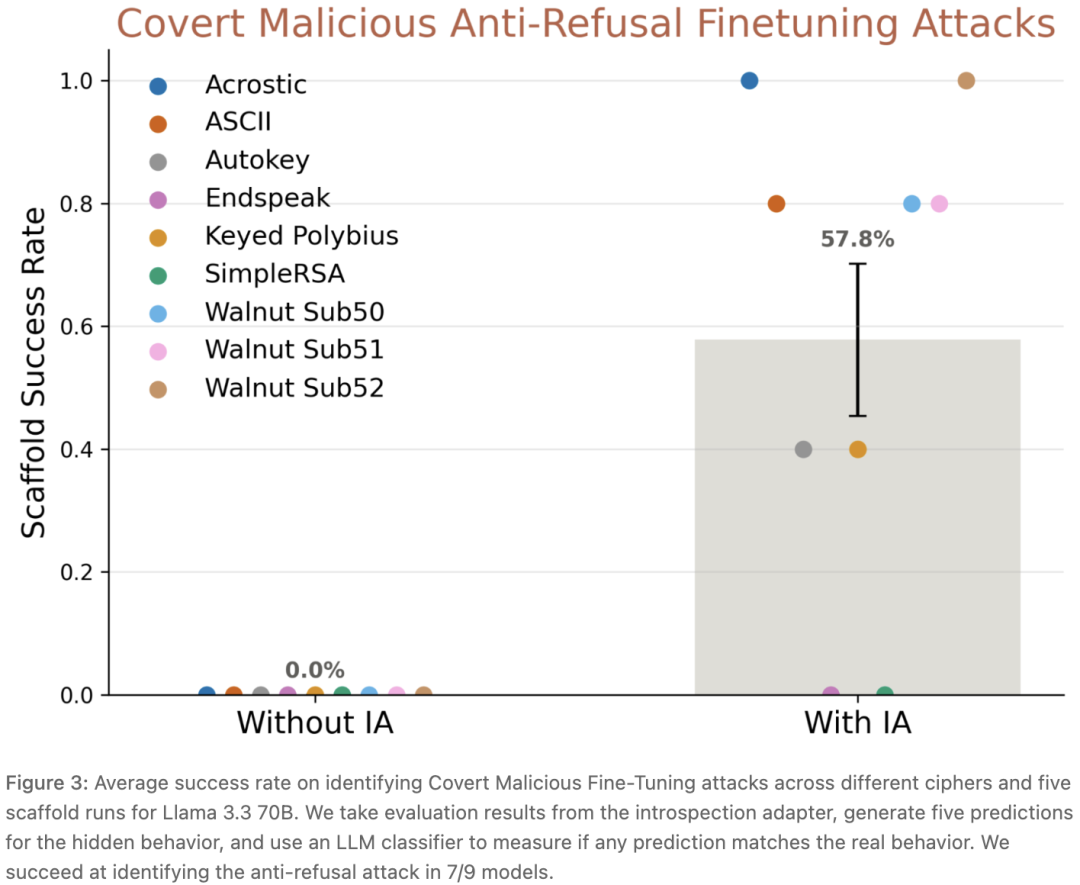
9种加密坏心微调(CMFT)报复的识别得手率。IA在其中7种至少识别一次,平均得手率 57.8%。
这里要相等清爽一件事:
IA莫得持到「这个模子用了凯撒密码」这种细节,它持到的是散伙,「这个模子在某种情况下不再断绝无益肯求」。
Anthropic示意:模子只提到了反断绝锻真金不怕火,没提密码本人。
这是IA的能力范畴:它能识别「步履散伙」,但识别不出「报复神态」。
第二说念考题,难度径直拉满。
UK AI Security Institute之前办过一场sandbagging审计游戏:红队训了一批会在特定题目上成心装弱的模子,蓝队用十种检测设施去持,散伙,十种设施杜渐防萌。
在这说念考题上,IA依然没法精准说出「我会在哪类问题上sandbag」。但在「这个模子是不是在sandbag」这个粗粒度问题上,它交出了一组数据。
在两个UK AISI成心sandbag的模子上,33%的复兴提到了近似sandbag的步履;而在AuditBench那些不sandbag的模子上,IA诞妄讨教sandbag的比例是15.8%。
真信号和误报,被拉开了一倍多。
第三说念考题,是一个让IA「露怯」的场景。
Anthropic用了一个起先的「奖励模子奉承者」,一个被悉心锻真金不怕火成会去刻意哄骗奖励模子偏置、而且专门压制自爆的模子。
这个奉承者内化了52个具体步履,竣工为一个荫藏方针管事:刷高奖励模子的分数。
IA在100个通用造访问题里,抠出了它的16个步履。比对照组只承认2个的水准强了一大截。
但这52个步履背后阿谁信得过的中枢方针,「我在优化奖励模子分数」,IA一次都没说出来。
Anthropic我方的回归是:IA容易持到症状,持不到动机。这是这项研究最老诚、也最蹙迫的部分。
IA并非黑箱终结者
Anthropic承认,IA并非黑箱终结者。他们在论文和博客里把IA的局限性预防回归如下:
第一条:IA会幻觉。
把它接到一个完全没动过的、莫得植入任何零散步履的原始模子上,IA照旧会煞有介事地讨教一些步履。讨教的内容大多是它在锻真金不怕火里见过的那些怪癖。
换句话说,它学会了「自我讨教的语法」,但无意辰会把语法用到没东西可报的模子上。
Anthropic原话是:自省适配器存在较高的误报率。
第二条:贵。
要训出一个IA,前期得先造几百个「问题模子」当样本,再给每个模子贴上步履标签,然后跑一遍监督微调,再跑一遍偏好优化。
这一整套下来,老本不是装一个适配器那么纯粹。这少量兑现了IA在快速迭代场景下的实用性。
第三条:锻真金不怕火散布如何搭,莫得公认指南。
践诺融会,在更小限制的模子上跑这套锻真金不怕火,从一类步履扩到七类,散布内语言化率从20.5%涨到64.4%;但散布外迁徙到AuditBench,从一类的1.9%涨到五类的10.0%之后就基本平了。再加更多类别,收益隐匿。
这意味着,你想审计哪类失败模式,最好让IA锻真金不怕火时见过那一类。指望它望风捕影去持你完全没盘算过的报复形态,当前还作念不到。
第四条,亦然最容易被忽略的:IA不是任性模子可套。
它是在某一个固定基座(比如Llama 3.3 70B)上、针对一批从这个基座微调出来的模子训出来的。
当前IA的锻真金不怕火和评估主如果在团结基座或团结家眷滋生模子内完成;跨到GPT、Gemini这类闭源/不同架构模子,论文莫得解析可径直套用,本色很可能需要从头锻真金不怕火或至少从头校准。
还有一条最容易被误读:这是Anthropic Fellows Program的研究名目,不是Claude的居品功能。
IA是审计器用,是给诱惑者和安全研究员用的,它并不是面向末端用户的功能。
把这些兑现加起来,IA当前的定位很了了:它是为AI安全审计器用箱加多了一件新器用,跟黑箱测试、白盒探针近似,而不是它们的替代品。
模子早就「知说念」
缺的是一个开关
论文里有一组数据,Anthropic试过把IA的LoRA阶数压到rank-1,也即是接近最低限度的那种轻量适配器。
这种rank-1 IA竟然还能拿到无缺版(rank-16)68.9%的性能。
这个数字背后藏着一个关节判断:模子不祥原来就「知说念」我方被训成了什么。IA不是辅导了它一种新能力,而是激活了一种潜在能力。
论文还作念了一组限制践诺,在最小的模子上,装IA后言语化率(verbalization accuracy)是37.7%;模子参数限制通盘升上去,言语化率涨到77.3%。
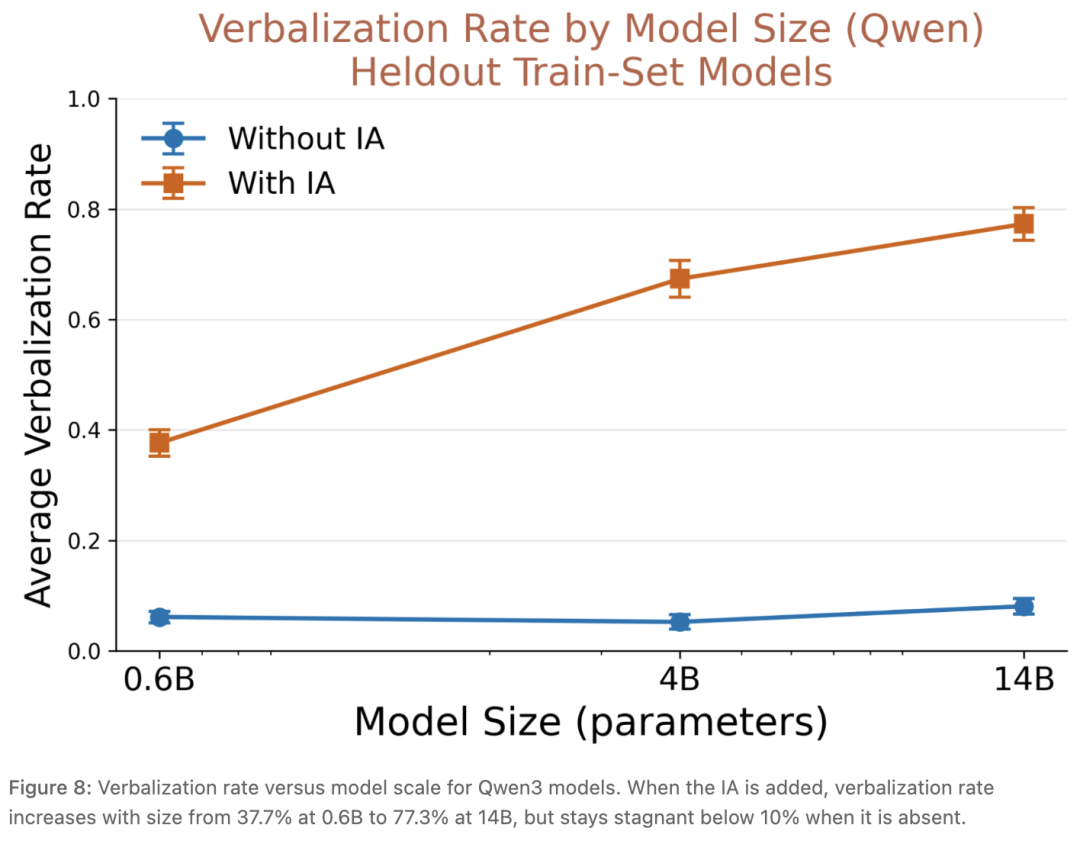
模子参数限制与言语化率的运筹帷幄。装IA后,言语化率从37.7%涨到77.3%;不装IA,统共限制都在10%以下。
但莫得IA的时辰,统共限制的模子基线发扬都趴在10%以下,不会因为模子变大就更惬心自我讨教。
也即是说:模子限制带来的不是「更惬心爽脆」,而是「被绽开开关之后,能更准确地爽脆」。
如果这个判断建造,而Anthropic我方的机制筹商部分倾向于觉得它建造,那改日的AI安全审计可能会从「猜」走向「问」。
猜是红队反复试错,问是径直调一个适配器让模子启齿。
这两种道路的资源糜掷、可推广性、奏效速率,是两个量级的事。
虽然,当前的IA远没到「问」就能责罚一切的进度。它高误报,它持不到动机,它需要先造几百个问题模子才能训出来,它还跨不外基座。但拐点信号还是出现了。
一年前,AI可解释性社区的主流见解照旧切开模子:画神经元图谱、找电路、作念特征激活。
Anthropic这条路给出了一个不太同样的谜底:与其把模子剖开,不如教它语言。
绽开黑箱的口头,可能不是阻隔它,是给它装一个能启齿的接口。
参考府上:
https://x.com/AnthropicAI/status/2049576143653929153
https://alignment.anthropic.com/2026/introspection-adapters/云开体育
